
Software security as a system control problem
Using Nancy Leveson’s generic control loop and systems theory to propose a control system for software security.
I’ve been thinking about the application of systems control theory to software security, and would appreciate feedback on whether I’m adding something, missing a trick or just stating the obvious.1
The problem: teams still chase secure software by asking developers two questions — did you build using security requirements from threat modelling and policy, and did you fix what the security tooling found? The trouble is that even if the answer to both questions is yes (which it rarely is because velocity is important too), the same specification, testing suite, tools and environment, handed to different developers and their AI agents, produce different code. The code that goes into production will be a special snowflake of objects, function calls and data structures all hackable in ways that may or may not have been imagined when the policies, threat model and tests were written.
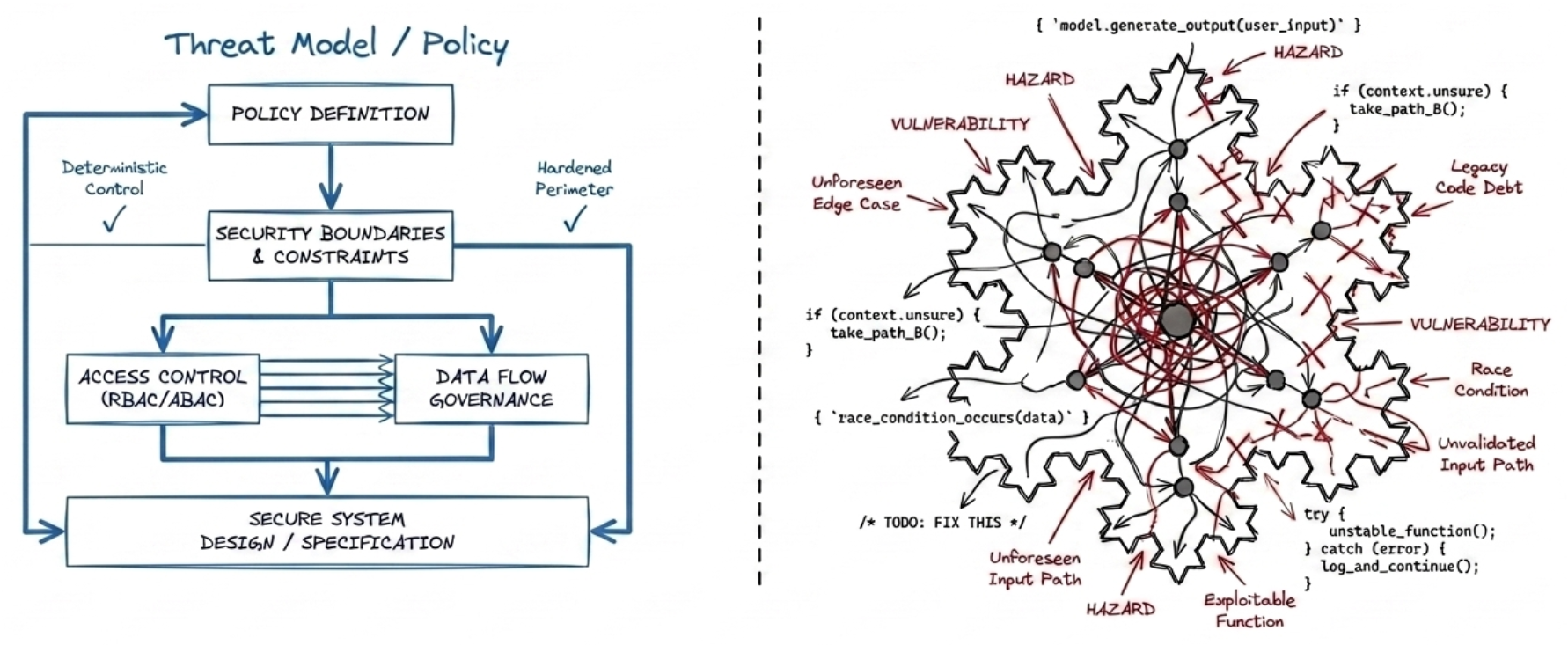 Figure 1 - Policies and threat models are just statements of belief; the code is the real architecture.
Figure 1 - Policies and threat models are just statements of belief; the code is the real architecture.
The cause: three things drive this. First, the code is the real architecture — not the diagram in a threat model or specification, which was only a statement of belief. Second, the architecture is the sum of thousands of small choices made by the people and AI models writing the code, and those choices vary with training, experience and values (see Simon Wardley’s work if you’re wondering whether AI can have ‘values’, and why it matters). Thirdly, traditional reductionist approaches to security assume incidents stem only from individual weaknesses in the code. But security incidents in complex, modern software are caused by malicious actors and their interactions among system components, often when those individual components are not, by themselves, inherently weak.
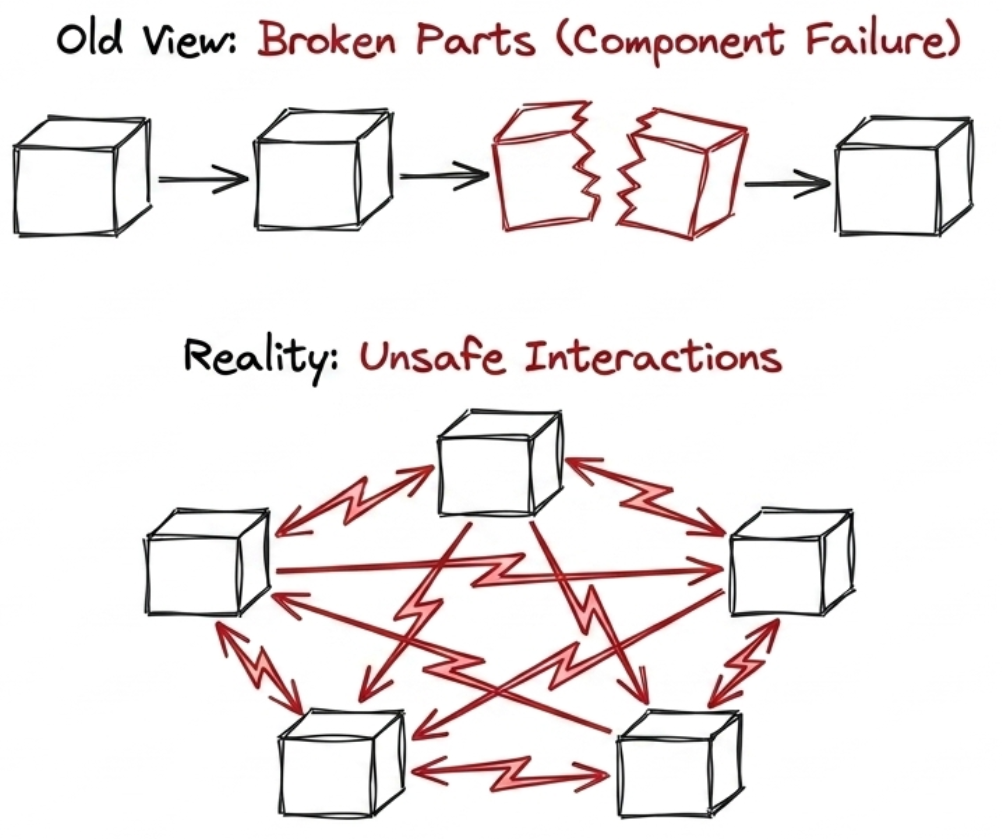 Figure 2 - Ultimately, security is not a component-vulnerability problem but a system-control problem.
Figure 2 - Ultimately, security is not a component-vulnerability problem but a system-control problem.
The solution: So securing software can’t just be about making each component predictable and secure; it’s a control problem. The job is to find the hazardous states and build a control structure — across the developer, the AI, the IDE and the CI/CD pipeline — that enforces constraints on insecure interactions. The system being controlled is the codebase and its deployment. The goal is to make software consistently harder to attack by having the IDE bind the AI’s output in real time, and for the CI/CD pipeline to act as a default-blocking gate — a violated constraint can’t reach production except through an exception that is scoped, logged and time-limited.
Proposal: a hierarchical control structure
Higher levels set constraints on the levels below; lower levels feed information back up.
Figure 3 — Each controller enforces constrains on the one below using it’s process model and updates its beliefs based on observed reality. The AI is both a controller (writing code) and a controlled process constrained by the IDE.
The controllers
Every controller, human or machine, works from a process model — its picture of the system’s current state — and incidents happen when that picture drifts from reality.
- The developer holds the intent, but their picture can be wrong (e.g. misreading how input is sanitised).
- The AI harness writes and reviews code from its training and prompt context, so a wrong picture means unsafe suggestions. Guardrails and prompt constraints are its first control loop — but it’s a black box: its reasoning is opaque and probabilistic, so we can’t rely on it to enforce anything. That’s exactly why it needs a deterministic supervisor downstream.
- The IDE is the fast feedback loop and the boundary between the developer/AI and the code. As code is written it checks constraints locally, and when something unsafe appears (say, a vulnerable SQL query) it pushes back immediately — correcting the developer’s and the AI’s picture before anything is committed.
- The CI/CD pipeline is the deterministic gate. It doesn’t matter whether the developer misunderstood something or the AI imagined it was safe: the checks run, and a violated constraint fails the build. This isn’t a physical, unbreakable barrier — it’s software the organisation owns — so the point isn’t that it can’t be bypassed, but that bypassing it is a deliberate, immutable, highly visible and expiring exception rather than an invisible one.
The constraints they enforce
Instead of ‘we’ll scan for vulnerabilities’, we state explicit constraints, and use the improved abilities of AI to reason about the context of the code and re-architect it. With AI, the controllers stand a chance of enforcing increasingly strict constraints while maintaining developer velocity and experience as first-class citizens. Examples may include:
- constraint 1: untrusted data must never reach a database without parameterisation.
- constraint 2: no hardcoded secrets in the source repository.
- constraint 3: the AI must not commit changes to authentication logic without a second, human sign-off.
| Current security practice | Systems control approach |
|---|---|
| Linear chain of events and isolated components | Emergent properties and complex interactions |
| Testing components and finding bugs | Enforcing constraints and receiving feedback |
| Reactive patching throughout the pipeline | Pro-active real-time, blocks for violated constraints |
| Developers, AI and security tools expected to be perfect | Every part of the software development system treated as a probabilistic hazard requiring deterministic supervision |
A constraint you can’t scan for
The three constraints above tend to be the easier kind (albeit harder at scale) as most software developers have access to security tools to check each one. The real test is a constraint no scanner reliably catches. Take broken object-level authorisation (BOLA), the API bug OWASP ranks number one: an attacker, authenticated as themselves, changes an object ID in a request and reads or changes another user’s record — because the handler never checks that the record belongs to them. Few build-time scanners catch it reliably, because the missing authorisation check is the bug, and whether a check is even needed depends on what the data means.
Using a hazard analysis technique called System-Theoretic Process Analysis (STPA), start with the loss, not the control. The loss is a user reading or changing another user’s data; the hazard is any request handler that returns or changes a record without checking that this user is allowed this record; so the constraint is that every access to a user-owned resource must carry an authorisation decision tied to the user, the record and the action.
You can’t prove that with a scanner - whether each handler got it right is a question of meaning, not syntax. So don’t try to catch the missing check; design it so the check can’t be skipped. Route all data access through one gate that won’t run a query unless you tell it who’s asking and what they’re touching. An unscoped query no longer compiles, and ‘forgot to authorise’ stops being a state you can reach. It’s the same trick as constraint 1 - where parameterisation makes injection impossible to express - but we apply it to a harder problem. Each layer then enforces the part it can check, and CI/CD proves deterministically that no code reaches data outside the gate.
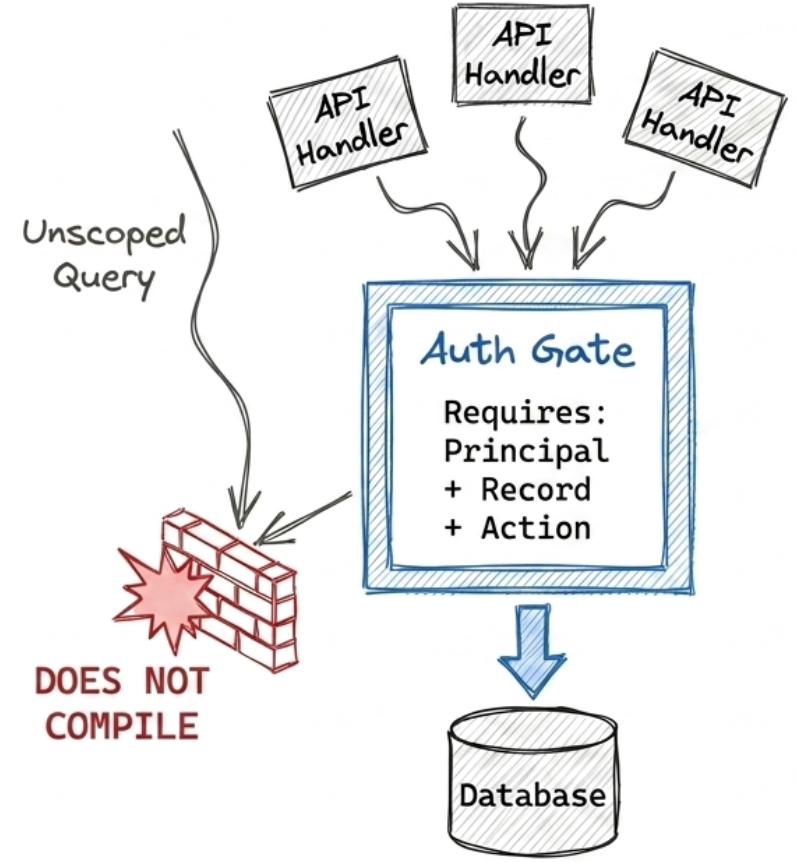 Figure 4 — Designing the hazardous state out. Every data path runs through one authorisation gate that needs the principal, the record and the action; an unscoped query has no path to the data — it doesn’t compile.
Figure 4 — Designing the hazardous state out. Every data path runs through one authorisation gate that needs the principal, the record and the action; an unscoped query has no path to the data — it doesn’t compile.
What no gate can prove is whether the rules themselves are right — ‘an order is readable by its owner and by same-region support staff’. That’s a human judgement. But the payoff is that the judgement now lives in one small, reviewable place instead of being scattered across every handler. The key point is that the control structure doesn’t remove trust in the developer or the AI; but it shrinks the surface that trust has to cover. Two things are needed to keep the gate honest: it must fail closed, so an unrecognised data-access path breaks the build, and it must reject ‘system’ callers that quietly switch authorisation off.
My belief that needs testing and I welcome feedback, is that this general move is repeatable: take a constraint you can’t check directly, find a structural version you can, push it down until the exploitable state can’t be expressed, and keep human review for the small part that’s left.
This article was published on LinkedIn, please give it a like or share there, or even better let me know what you think.
I know teams developing safety and mission critical software who already adopt modern systems control theory although I do not currently have visibility of how they are thinking about security control loops for developers and AI coding tools (which is the focus of this article). ↩